
A distributed system is a set of computers in a coherent system working together in such a way that for an end user it seems like they are interacting with a single computer. In the background, a complex network of computers handle data processing, storage of data, data replication and process execution in a coordinated manner. Distributed computing hides the complexity of a system from the end user. It also offers the flexibility of scaling the system when needed. However, there are challenges too. Specially for interoperability, security and data consistency. Luckily, there are some well known protocols to address these issues. Protocol means a set of rules that helps ensure process completion and minimizes risk. These protocols are implementation independent. It is up to system designers to decide how they will implement it and what kind of trade-offs to make.
CAP Theorem
CAP stands for Consistency, Availability and Partition Tolerance. The theorem suggests that in a distributed system any 2 of these 3 qualities are achievable at a time. This is the trade-off we are talking about. System designers need to decide which qualities are most important for their system and design accordingly.
Commitment Issue
Imagine this scenario, a client is requesting for a transaction to a server. The server has 3 nodes. 1 coordinator and 2 participants. The coordinator needs to ensure all participants have completed the transaction process. These outcomes might happen:
- All participants receive the request, perform the transaction and return an acknowledgement.
- Some participants receive the request, perform the transaction but fail before returning acknowledgement.
- Some participant fail before receiving the request.
How do we address these issues? Well, there are commitment protocols.
2 Phase Commitment
In this protocol, the coordinator sends a commit message to all the participants. The participants returns ready if they can perform the transaction. The coordinator then sends the transaction request to all participants.

3 Phase Commitment
What if the participant fail after returning ready. Here, we send a pre-commit message before sending the commit message. The participant switches to a commit state and waits for the commit message. If the participant fails to receive the commit message or didn’t perform the transaction after receiving commit, they can repeat the commit process.

Quorum
Quorum means a minimum number of participants or votes required in order to complete a process. Let’s say, we have 6 computers responsible for storing data. Now, how do we ensure that when a client reads data from any of these computers will get up-to-date data all the time. First of all, we can implement a lock and write process. It means, we lock all 6 nodes and make sure to write data to all 6 of them. But, if another client needs to read data from these computers, they need to wait after all the write process is complete. This introduces a large overhead.
The concept of quorum is that we don’t need to write data into all the nodes. Let’s say we write data into at least W nodes and read from at least R nodes. If we have n nodes in our system then:
This formula ensures that when we read data from R nodes, at least 1 node will provide the latest value.
Consistency
We can see that stored data might become different across different nodes in a distributed system. Hence, we have 2 consistency strategies:
- Strong consistency: Ensures all the nodes have same data.
- Weak consistency: Some nodes may have stale or outdated data and does not guarantee data will ever become consistent.
In cloud computing, they follow a special form of weak consistency called Eventual Consistency. The data might be stale for a while but it is guaranteed that it will become consistent over time. One good example of Eventual Consistency is Amazon DynamoDB. There is also Causal Consistency where consistency is maintained in terms of causal order.
Event Order
But what is causal order? In distributed computing, the order of events is often not calculated with typical timestamps. The time of each node might be slightly off which might cause issues. To tackle this problem computer scientists came up with Logical Clock and Vector Clock.
Logical Clock
Simply assign a number with every event. The number increments by 1 with each following event. If event A occurs before event B then B must have a greater number than A. Let’s say, a different event C is received from another node which occurred after B but C is less than B. Then, we take the event number of B, increment by 1 and assign it to C. This is called Logical Clock Correction. The algorithm is suggested by a scientist named Lamport.
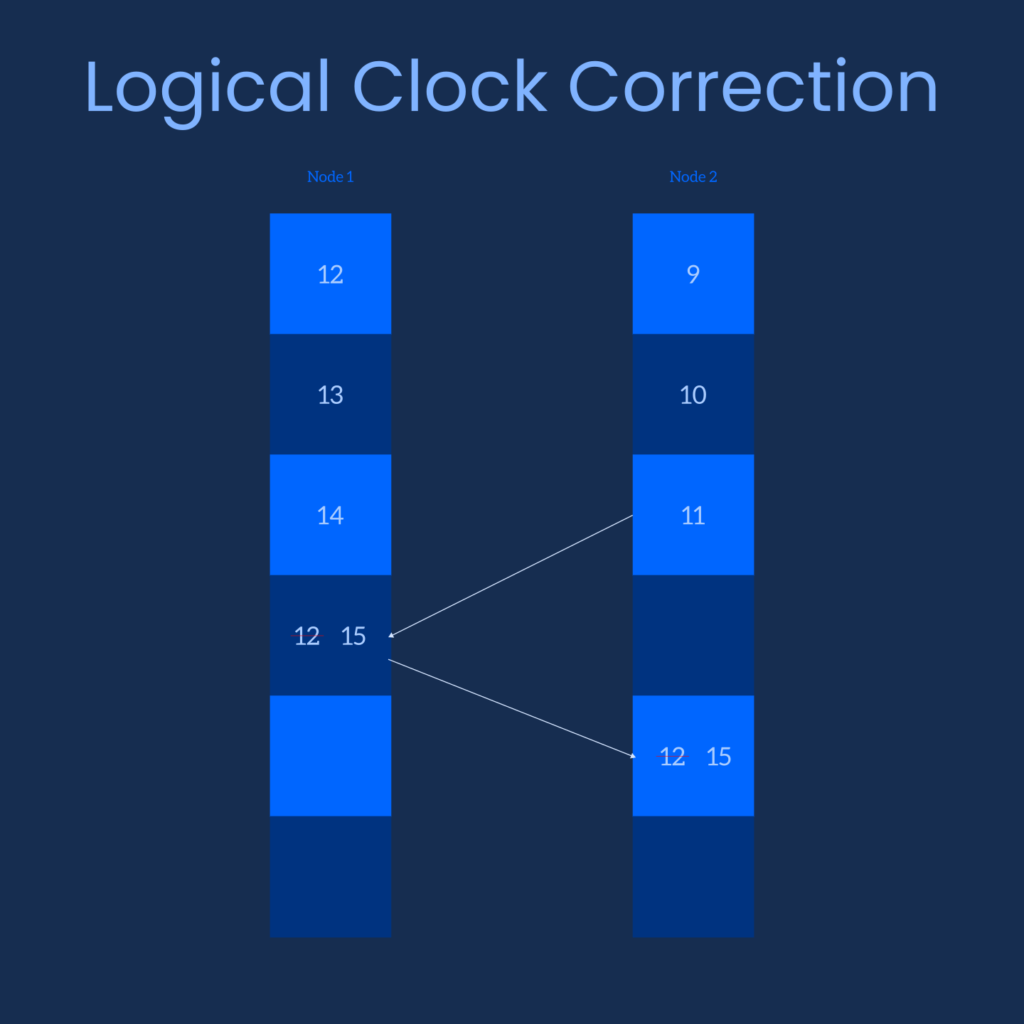
Vector Clock
The concept of Vector Clock is quite similar. In this case, each node contains a vector (perhaps you can call it a list) of event numbers. Each index of the vector represents a corresponding node. When a node sends an event request, it also embeds its’ event vector with the request. The receiving node compares the values of the 2 vectors and if it finds an event number greater than that is stored on its’ own vector it updates the number.
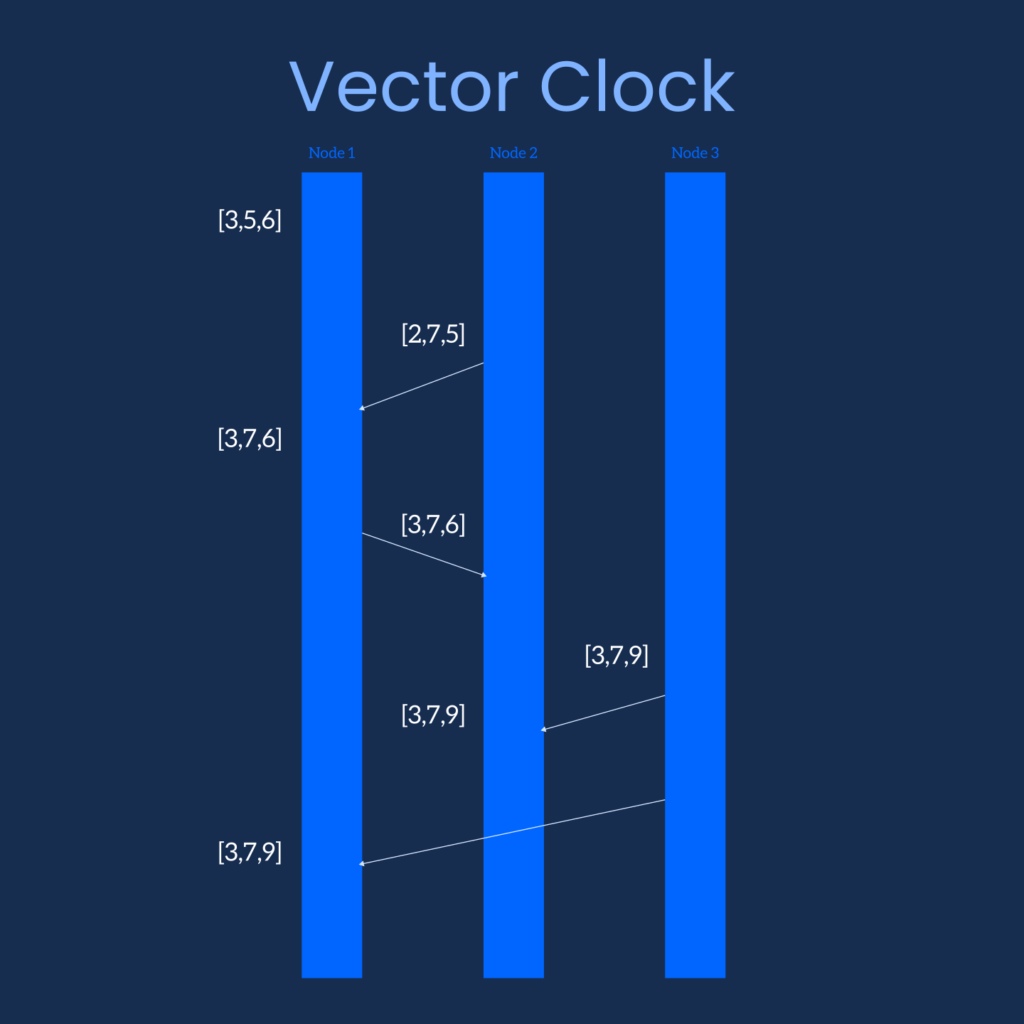
Thus, we have event ordering according to event number or event vector. This ordering does not necessarily indicate a causal relationship. But we can determine which event occurred before which.
In this post, we discussed about some of the fundamental concepts related to distributed computing. We learned about CAP theorem. How nodes communicate in a group. How data consistency is maintained and what kind of strategy to follow. Finally, a little bit about event ordering to determine the order of events occurred in a node.



